Joona Laine from Spatineo chose this as subject of his master’s thesis (Crop identification with Sentinel-2 satellite imagery in Finland). What kind of problems he solved and what were the steps to ensure that the results were high quality? How does crop identification work with neural network and what are cloud pixels?
The need for Field Monitoring and Crop Identification
There are 22 million farmers and agricultural workers in the European Union (EU) agri-food sector. To ensure a decent standard of living to the farmers, EU is supporting them with the common agricultural policy and In order to ensure that the subsidies are divided equally and without misuse, the CAP subsidies must be controlled by the local authorities within Integrated Administration and Control System (IACS). At least 5% of the agricultural parcels, that the subsidies are applied for, have to be monitored for each year.
This monitoring has been done traditionally by inspectors actually going on site, to check the field and making sure that all information gives in the CAP application is valid. Checking 5% of all the fields manually is a huge effort for local authorities, and this is where satellite monitoring comes is as a “easier” solution.
Satellite imagery, and specifically Sentinel-2 imagery, was optimal choice because the cost effectiveness was unparalleled, the spatial resolution (pixel size) was suitable for crop monitoring and high revisit frequency was well suited for continuous monitoring. Other options for the source material would’ve been aerial orthoimagery and drone imagery.
From all possible satellite imagery options Sentinel-2 was chosen because the frequency the images are taken. Images taken in 2-3 day intervals gave chance to glance through clouds, as in Finland there can be over 200 cloudy days annually. European Space Agency (ESA) also has made the Sentinel imagery highly and openly available.
How did a machine learn to identify the crops?
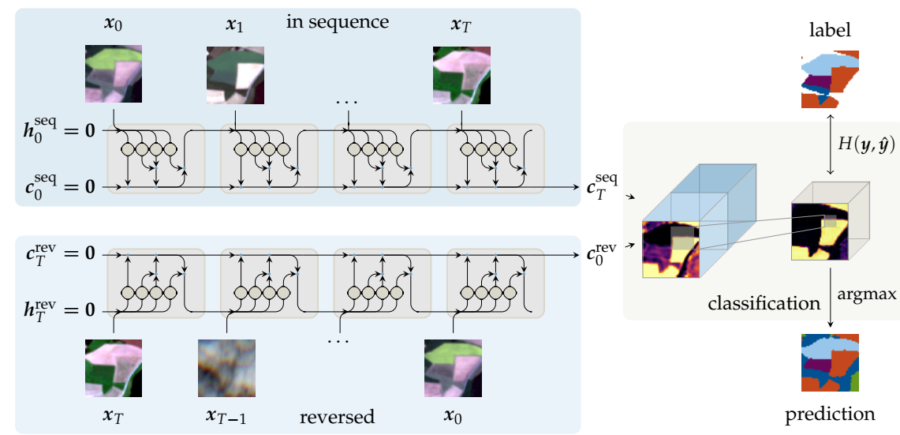
Classification was based on pre-learned material, which the algorithms based their assumptions on when evaluating the imagery. Algorithms were “shown” different features consisting of multiple images representing the parcel in hand, and told what was the crop in question in each feature. First fhe algorithm were just shown feature of the parcel and they had to “guess” which crop was in it. Eventually as the algorithms were told each time if they were right or wrong, they were able to evolve better and better in guessing the crops.
Machine learning was used to classify different crop from each other. During the first stages of the project, it was still unclear with machine learning classification algorithm would perform best. Support Vector Machines (SVM), Random Forest (RF), Multi-layer Perceptron (MLP) and Convolutional Recurrent Neural Networks (ConvRNN) were the algorithms tested during the project and most of them were capable of basic classification of the largest classes of crops. Eventually it became clear that SVM, ConvRNN and MLP were most suited for the classification, and hence they were used for most part of the study.
SVM and RF represent more of a traditional way of machine learning classification, while MLP and ConvRNN utilize neural structure of deep learning. This might be the reason why MLP and ConvRNN were more prominent than other methods.
How to Improve Crop Identification Success Percentage Rate?
During the work it was clear that there were great amount of variables that made harder to identify crops. Some of these variables were just minor hurdles, but some needed hard work to be overcome. Down below there are the issues that required most effort to be fixed during the project.
Cloud interference
Cloud were the hardest problem from the beginning, since they made most of the source images technically useless without modification. After some research it was clear that cloud masks would have to be used, in order to make source material usable. Eventually two cloud masks, one snow mask and one cloud shadow mask were utilized. Although ConvRNN was able to detect clouds automatically.
Appearance dependent of growth cycle
Plants and crops have different appearances dependant on their growth period. This basically means that one image per field wasn’t enough, as some of the crops might have had almost identical appearances at the beginning of their growth. Time series of images from each phenological state (stage of the growth) was used to differentiate the crops from each other.
Imbalance of class distribution of the crops
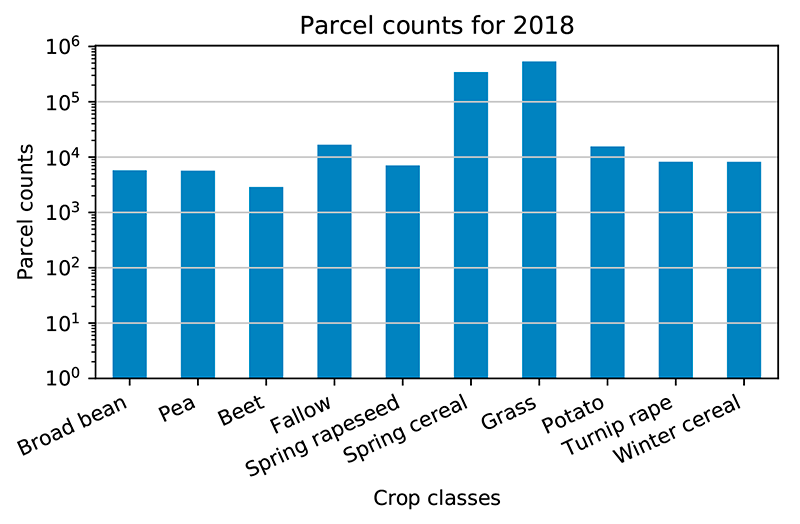
In the training material for the algorithms there were two classes of crops that had the overwhelming majority. This uneven class distribution made is hard for the algorithms to identify accurately those crops that didn’t below to the two dominant categories. There were two possible fixes for this problem: either delete some part of the dominant categories or increase the number of lesser categories from the training material.
Both ways just adjust the ratio between the classes, and after some testing the increasing of the lesser categories proved to be more effective method.
Results of crop identification
After all the major hurdles were overcome the accuracy of the algorithms rose up to 92%. The goal for the whole project was at least 95%, since 95% is considered to be the limit where the automatic identification could be efficient alternative for the manual inspections done nowadays.
These identification methods proved to be effective and operational in handling crop identification process. In order to make it even more viable, more research and testing would be recommendable, but viability of the method has now been proved. Analysing satellite imagery will be a very viable alternative to traditional inspectors visiting the fields.