
At the start of 2019 our client the Department of the Built Environment of the Finnish Ministry of the Environment needed to set up an API to offer spatial planning datasets produced in the Kuntapilotti pilot project. The pilot was one of the work packages of the larger Maankäyttöpäätökset (Land use decisions) project. One of the goals of the project was to develop and test a new data model for digital spatial plans and how the spatial planning data in produced in this format could be received, validated, stored and published as an INSPIRE compliant Download Service using OGC Web Feature Service (WFS) 2.0 standard and the INSPIRE Planned Land Use GML application schema.
The municipalities participating in the pilot project provided a limited set of spatial plan data in using the new data model under test, submitted the data for validation and storage to the Finnish national Geospatial Platform (Paikkatietoalusta, PTA) developed and operated by the National Land Survey of Finland. However, there was a key piece still missing from the workflow: the data needed to be automatically transformed into the INSPIRE Planned Land Use GML format and made available via a WFS service. There was no time to waste as the entire process from the creating the plans to publishing them needed to be validated and reported within the timeframe of the pilot project scheduled to be completed by summer 2019.
We at Spatineo gladly took the challenge of building the publishing database and the API as we had a lot of experience in using a combination of GeoServer, Hale Studio and PostgreSQL/PostGIS database for creating WFS services for various geospatial datasets, including INSPIRE data. We were also very familiar with many components of the Amazon Web Services (AWS), which is where we have been running our own SaaS products and various other projects since 2011. The thing we wanted to get more experience from was how easy and fast would it be to create a system for setting up the necessary servers, software, configurations and data in the Amazon cloud, and keeping them automatically up-to-date with the new incoming data and configuration changes according to the contiuous deployment (CD) methodology.
Our plan was to wrap the GeoServer spatial data API server application and the PostgreSQL/PostGIS database into their own Docker containers and set up an automation pipeline to deploy them into the Amazon cloud. We also wanted to automate the entire building and deployment processes of both components so that the GeoServer configuration as well the pilot project dataset would be wrapped inside the containers. This way we could easily build and run the same server and database containers both in local test environment and in the operational cloud environment.
We used Amazon Elastic Container Registry (ECR) to manage the Docker containers and a combination Amazon CloudFormation to describe the necessary server infrastructure and Amazon Fargate to deploy and run the GeoServer and PostgreSQL containers. The Amazon AWS CodePipeline was used to start the automatic build and deploy processes of the both containers when configuration and data changes were detected, and thus implement a seamless continuous deployment system for the spatial data provisioning API.
GeoServer container building was triggered by changes in a Github repository containing the GeoServer configuration data directory including complex feature database-to-GML mapping files created with Hale Studio. The database structure of the internal PostGIS database schema used by the Geospatial Platform was mapped into INSPIRE Planned Land Use GML application schema feature types to be used by the GeoServer AppSchema plugin for making them available as a WFS service. AWS CodePipeline published updated container to Amazon ECR and initialized deployment process.
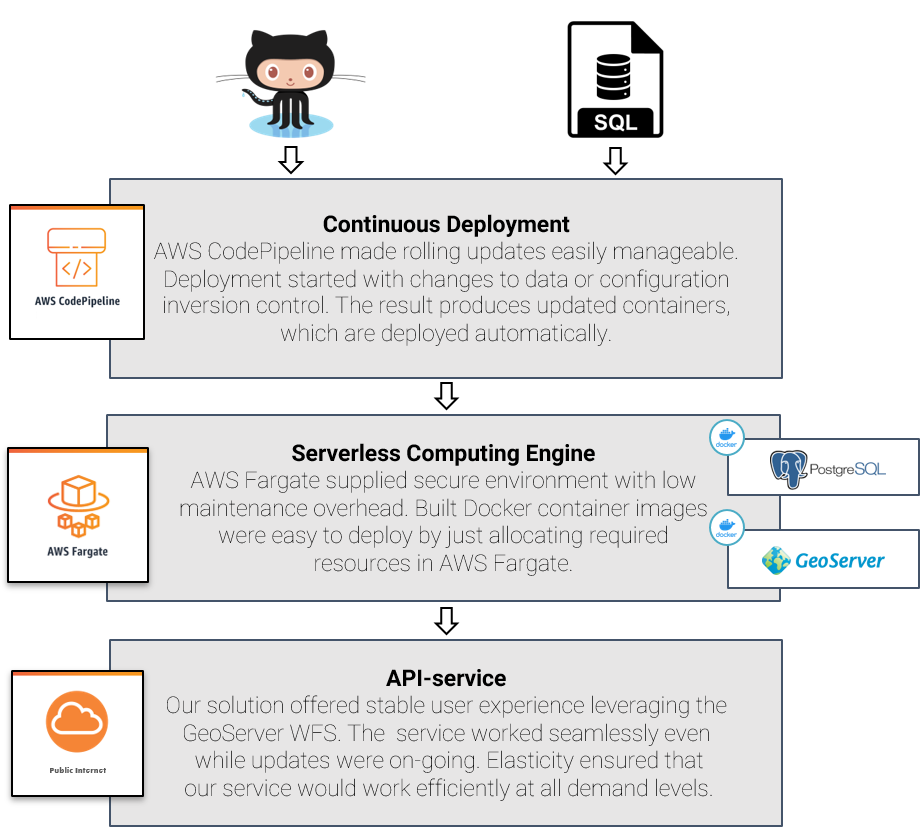
The datastore in this pilot was implemented as a self-contained Docker container containing both the PostgreSQL/PostGIS relational database management system and the provided data content. Updated dataset from the Geospatial Platform was uploaded to Amazon S3 bucket as a PostgreSQL database dump file. AWS CodePipeline combined with AWS Lambda function enabled automation which was set up to detect changes in this file and trigger a process to construct a Docker container with PostgreSQL and the embedded database dump file. As with the GeoServer container, the process ended with updated the container in Amazon ECS. A script was set up to automatically load the dump file into the database on starting the database container.
It should be noted that the data volume in this pilot project was reasonably small, and thus the database Docker container size could be kept under the 10GiB size limit imposed by Amazon ECS by default. For operational systems with larger and scalable storage volumes, it would make sense to download and load the data dump directly from S3 and not to store it within the container, or even use Amazon Relational Database Service (RDS) for running the PostgreSQL database. The benefit of the in-container dump in this case was that the developers could run and test the entire application on their own laptops including the real database content.
Designing, building and testing the entire system described above for both the GeoServer and the database components took less than a week of working time from a single person, and the system was running without hiccups until it’s planned shut down in about 8 months.
What do we learn from this project?
The first giveaway from this project for use was the recognizing the importance of infrastructure management and how capable the cloud automation tools are nowadays. Implementation was built and managed with Amazon CloudFormation and it made doing changes and updates really easy. Infrastructure-as-code also acts as easy to understand documentation for the developers describing exactly which resources and components are required and how they are bound together.
CloudFormation’s only weakness is its verbose nature, which results in a massive YAML configuration, even if the service infrastructure is moderately small. Fortunately, the Amazon also provides AWS Cloud Development Kit (CDK) to help with this, and we will definitely consider using it in future implementations.
Another thing worth mentioning is Fargate service and how easy it is to use. Container-as-a -Service (CaaS) streamlines the infrastructure deployment in projects utilizing container technology. Containers enable agile development in well-controlled local environments identical with their operational counterparts without operating system and runtime environment related challenges.
Spatineo is part of AWS Partner Network
We have accumulated experience on how to utilize Amazon Web Services for quite some time, and decided to joined the Amazon Partner Network to formalize and further improve our expertise offerings on the Amazon cloud based solutions. Our experts are currently participating in a training program to get official Amazon certifications such as AWS Certified Solutions Architect – Associate to prove the level of our knowledge in Amazon cloud technologies. As AWS Partner Network member we are well equipped and ready to help you solve your most challenging geospatial data provision and processing needs using the world’s leading platform for building cloud-based services.