Avoimen datan käyttö ja tarjonta on kasvanut viime vuosina nopeasti ja tämä kehitys jatkuu. Mutta miltä näyttävät avoimen datan käyttäjät sen tarjoajan näkökulmasta, ja miten käyttäjiä ja datan käyttöä voidaan analysoida? Tässä blogikirjoituksessa käyn läpi joitakin näihin kysymyksiin liittyviä perustekijöitä ja esittelen erään avoimen datan palvelun kohdalla saatuja tuloksia, kun tehdään ns. lokianalyysiä. Tämä on kuitenkin vasta alku, sillä seuraavissa kirjoituksissa pääsemme eteenpäin mm. sellaisessa mielenkiintoisessa aiheessa kuin käyttäjien ja käyttäjäryhmien profilointi koneoppimismenetelmillä.

Avoin data ja rajapinnat
Avoimen datan käyttö perustuu rajapintoihin. Rajapinta voi yksinkertaisimmillaan olla selaimista tutun osoiterivin eli URL:n näköinen datapyyntö. Jos esimerkiksi haluan tietää missä kulkee juna, jossa kirjoitan tätä tekstiä, voin tehdä suoran datapyynnön selaimellani:
https://rata.digitraffic.fi/api/v1/train-locations/latest/36
Saan vastaukseksi eräänlaista koodia, josta selviää mm. junan IC 36 sijainti koordinaatteina:
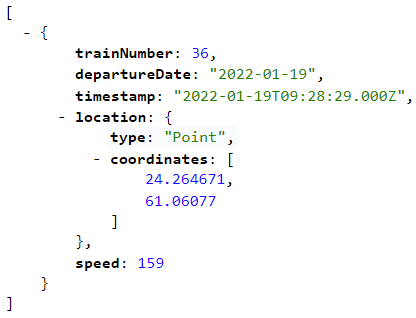
Tämän tiedon saamiseksi olisi toki kätevämpiäkin tapoja, esimerkiksi jokin mobiilisovellus, joka lisäksi näyttäisi sijaintini kartalla ja onko junani kenties myöhässä. Pohjimmiltaan kuitenkin nämäkin sovellukset käyttävät tällaisia rajapintoja ohjelmallisesti. Esimerkiksi mobiilisovelluksessa valitsen junani numeron listasta ja sovellus tekee saman datapyynnön (ja luultavasti monta muutakin) puolestani, purkaa vastaukset ja näyttää tiedot havainnollisesti. Tässä tapauksessa varsinaisen datapyynnön teki ohjelma, joka keskusteli rajapinnan välityksellä toisen ohjelman kanssa, ohjelman joka toimii Fintrafficin tietojärjestelmässä, luultavasti jossain internetin pilvipalvelussa.
Avoimen datan rajapintojen muoto vaihtelee ja rajapintaan liittyy oleellisesti kuvaus siitä, miten rajapintaa käytetään. On myös erilaisia standardeja tietyn tyyppisten tietojen rajapinnoille, esimerkiksi Spatineo Monitor analysoi paikkatietoihin liittyvien rajapintojen käyttöä, ja tällaiset rajapinnat on hyvin pitkälle standardoituja (esim. OGC:n WMS ja WFS).
Avoin data ja lokitiedot
Jokaisesta avoimen datan rajapintaan tehdystä tietopyynnöstä saadaan lokitiedot. Kerättävä tieto vaihtelee, mutta se yleensä sisältää ainakin pyynnön tekijän verkko-osoitteen (IP-osoite), eräänlaisen sovellustunnisteen (esim. selainohjelman nimen ja versiotiedot) ja pyynnön URL-tekstin sekä pyynnön ajankohdan. Nämä ovat ne tiedot, joista tässäkin blogikirjoituksessa käsitellyt analysoinnit lähtevät.
Toisin kuin useimmissa selaimella käytettävissä verkkosivuistoissa, avoimen datan rajapinnoissa ei juurikaan käytetä keksejä, jotka ovat kaikille tuttuja sivustojen hyväksymispyynnöistä. Käyttäjää ei myöskään monissa tapauksissa tunnisteta esimerkiksi rekisteröinnin tai käyttäjätunnuksen perusteella, joten lähtökohtaisesti em. lokitieto on varsin anonyymiä yksittäisen käyttäjän tasolla. Myöskin operaattoreiden verkoissa henkilökäyttäjien IP-osoitteet ovat usein vaihtuvia ja yhteys asiakastietoihin on vain operaattoreiden tiedossa. Toisaalta siis tällainen lokianalyysi on vähemmän tungettelevaa yksityisyyden suojan näkökulmasta kuin esim. yksilöivien keksien käyttö, mutta toisaalta avoimen datan tarjoajan näkökulmasta käyttäjän yksilöivä tunnistaminen ei ole edes välttämättä tarpeen. Useimmiten analysoinnissa ollaan kiinnostuneita käyttäjäorganisaatioista ja samankaltaisista käyttäjistä ryhmänä. Palaan tähän aiheeseen vielä myöhemmin tässä kirjoituksessa.
Verkkosivujen lokitietojen yleinen analysointi on itse asiassa melko perusteellisesti katettu. Lokianalysaattoreita on valtavasti ja on myöskin lokitietojen keruuseen verrannollisia tapoja saada tietoja sivustojen käytöstä, myös yksityiskohtaisempaa kuin edellä kuvattu lokitieto. Esimerkiksi Google Analytics perustuu sivustolle sijoitettuun analytiikkakoodiin. Verkkopalvelimesta kerätty lokitieto voidaan siis ajatella passiiviseksi ja yleisluotoiseksi, sivustosta riippumattomaksi tiedonkeruuksi. Toisaalta jos tarkastellaan vain yleisesti mistä ja milloin datapyynnöt tulevat, jää varsinainen datapyyntöjen kiinnostuksen kohde hyödyntämättä. Ongelmana on tietenkin se, että datapyynnön kysely, joka junatietojen esimerkissä oli osa URL-tekstiä, on jokaisesta rajapinnasta riippuvaa ja erilaista ilman standardointia. Toisaalta taas kiinnostuksen kohde olisi se mikä palvelun käyttäjissä kiinnostaisi hyvin paljon: esimerkiksi verkkolehdessä olemme tietenkin kiinnostuneita siitä minkä aiheisia artikkeleita lukijat lukevat. Tässä kirjoituksessa keskityn kuitenkin yleiseen lokitiedon tarkasteluun ja mitä siitä on mahdollisesti saatavissa irti avoimen datan käyttäjistä.
Avoimen datan rajapintojen erilaiset käyttäjät
Edellä huomattiin jo kaksi esimerkkiä siitä, että avoimen datan rajapintoja voidaan käyttää eri tavoin. Avoimen datan tarjoajan näkökulmasta erilaiset käyttötavat voidaan erotella ja tietoa voidaan hyödyntää datan käytön analysoinnissa. Yleisesti voidaan sanoa, että rajapintoja käyttävät toiset ohjelmat, usein automatisoidut ja säännöllisen aikataulun mukaan toimivat ohjelmat, joita voidaan kutsua myös roboteiksi tai lyhyemmin boteiksi. Jaotellaan niistä tyypillisimpiä:
- Yksittäisten organisaatioiden botit. Esimerkiksi yritys kerää avointa dataa säännöllisesti yhdistääkseen sen muuhun liiketoimintatietoonsa. Tällainen botti toimii useimmiten säännöllisesti, esimerkiksi suorittaa datapyyntöjä kerran päivässä tai tunnissa. Tällaiset datapyynnöt näkyvät lokitiedoissa yleensä yhdestä verkko-osoitteesta ja korkeintaan muutamasta sovellustunnisteesta tulleena. Verkko-osoite on hyvin usein pilvipalvelun osoite.
- Verkkosivustojen palvelinsovellukset. Esimerkiksi verkkolehti näyttää säätietoja osana sivujaan, mutta säätiedot haetaan avoimesta rajapinnasta säännöllisesti talteen ja yksittäiselle lukijalle näytetään tätä vaikkapa kerran tunnissa haettua tietoa. Tällainen verkkosivusto siis peittää rajapinnalta varsinaisen loppukäyttäjän ja näyttää lokitiedoissa samankaltaiselta kuin edellä kuvattu botti.
- Avoimen datan tarjoajan muut palvelut. Monet avoimen datan rajapinnoista ovat syntyneet sen tuloksena, että julkisyhteisöt ovat avanneet sisäisessä käytössä olleen datan avoimesti käytettäväksi. Tällöin on myöskin luonnollista, että datan tarjoajan muut palvelut voivat käyttää samoja rajapintoja kuin ulkopuolisetkin toimijat. Esimerkiksi ajantasaista säätilatietoa avoimesti jakavalla toimijalla voi olla omat säätilaa, sen historiaa ja ennusteita laajasti esittelevät verkkosivut. Tällainen käyttö näkyy lokitiedoissa ns. sisäverkon osoitteista tulleina pyyntöinä.
- Avoimen verkon muut botit ja tiedonkerääjät. Esimerkiksi hakurobotit (Google ja vastaavat) kahlaavat säännöllisesti avointa verkkoa läpi ja keräävät tietoa verkon sisällöstä. Näitä botteja ei yleensä tulkita avoimen datan varsinaisiksi käyttäjiksi. Spatineo Monitor tekee myös tällaista rajapintojen käyttöä testatakseen mm. palveluiden toimivuutta ja vaste-aikoja.
Osassa avoimen datan rajapintoja nähdään myös loppukäyttäjän eli tavallisen selainkäyttäjän käyttöä suoraan, ja monissa palveluissa näiltä tulevat pyynnöt onkin merkittävä ellei suurin osa pyyntöjen kokonaismäärästä. Tällöin selainsovellus tekee suoraan pyyntöjä rajapintaan, kun käyttäjä lataa sivun tai käyttää sivun jotain toimintoa. Silloin pyyntö näyttää lokitiedoissa tulleen suoraan käyttäjän verkko-osoitteesta, joka on tyypillisesti operaattorin vaihtuva verkko-osoite (varsinkin mobiiliverkossa) tai yhteisön verkko-osoite (esimerkiksi käyttäjä on työ- tai opiskelupaikkansa verkossa). Toisin kuin bottien tapauksessa tällainen käyttö näyttää enemmän satunnaiselta ja pistemäiseltä kuin säännönmukaiselta. Ajankohta tai ulkoiset tekijät vaikuttavat pyyntöjen määrään: juhannuksen alla säätietoja kysellään tavallista enemmän, ruuhka-aikoina liikennetilanne kiinnostaa tai talvimyrskyn uhatessa seurataan junavuorojen ja lentojen peruutusilmoituksia.
Avoimen datan käyttäjien organisaatioiden tunnistaminen
Seuraavassa käyn läpi erään suomalaisen avoimen datan palvelun lokitietojen pohjalta tehtyä analyysiä. Sen tavoitteena oli selvittää miten hyvin pystytään tunnistamaan datapyyntöjen taustalla olevat organisaatiot yksilöidysti ja erityisesti suomalaiset yhteisöt. Tarve on tyypillinen: haluamme tietää verkkonimiä pidemmälle mitkä asiakkaat käyttävät mitäkin palveluita ja kuinka paljon. Organisaatiotieto on hyödyllinen tieto siis data-analyysissä ns. dimensiona, joka on yhdistettävissä tässä tapauksessa palvelupyyntöihin ja niiden sisältöön (analytiikassa näistä puhutaan ns. faktoina). Esimerkiksi dashboard-tyyppisissä visuaalisissa raportointinäkymissä asiakasorganisaatio olisi ryhmittelevä ja rajaava tekijä, kun avoimen datan palvelun käyttöä analysoidaan.
Verkko-osoite pystytään pääsääntöisesti melkein aina yhdistämään verkkonimeen eli ns. DNS-nimeen (pl. aiemmin mainitut sisäverkkojen osoitteet). Samoin useimmille verkko-osoitteille saadaan summittainen sijaintitieto, joskin epävarma sellainen. Lähemmäs organisaatiotietoa päästään, kun louhitaan erilaisten verkon rekisteröintipalveluiden tietoja osoitteista ja DNS-nimistä vaihe vaiheelta poimimalla lisää tietoa. Perinteisiin internet-verkon rekisteröintipalveluihin päästään kiinni WHOIS- ja RDAP-protokollilla, tosin tiedot ovat usein puutteellisia ja laadultaan vaihtelevia. Sopivasti tietoja yhdistelemällä erilaisilla päättelysäännöillä ja jopa koneoppimismenetelmillä voidaan kuitenkin päästä tunnistamisessa eteenpäin. Esimerkkitapauksessa oltiin kiinnostuneita suomalaisista yhteisöistä, joten voitiin käyttää myös PRH:n eli Patentti- ja rekisteröintihallituksen tietoihin kohdistuvia automatisoituja hakuja ja tunnistuksia. Tätä kautta saadaan tunnistetulle organisaatiolle myös mm. yhteisötyyppi ja toimialatiedot, jotka ovat myös hyödyllisiä dimensioita jatkoanalysoinnissa. Lopputuloksena saavutettiin varsin kohtuullinen kattavuus suomalaisten organisaatioiden tunnistamisessa ja seuraavassa esittelen näitä tuloksia.
Kyseisestä suomalaisesta avoimen datan palvelusta tarkasteltiin neljän viikon ajanjaksoa vuonna 2021. Palvelun käyttäjät ovat pääosin suomalaisia organisaatioita ja palvelun omistaja on erityisesti kiinnostunut näistä asiakkaista. Palveluun kohdistui mainittuna aikana n. 5,4 miljoonaa pyyntöä vajaasta 13 000 verkko-osoitteesta. Tavalliseen tapaan lähes kaikille verkko-osoitteille voitiin nimetä jonkinlainen verkkonimi ja useimmille summittainen sijainti.
Verkko-osoitteiden organisaatioista pystyttiin tunnistamaan kaiken kaikkiaan 75,5%. Pyynnöistä voitiin nimetä 90,5% (n. 4,9 miljoonaa) tiettyyn organisaatioon liittyväksi ja 71,7% (n. 3,9 miljoonaa) voitiin kohdistaa suomalaiseen yhteisöön Y-tunnuksella. Samalla pystyttiin arvioimaan, että enintään 8,4% (n. 0,5 miljoonaa) datapyyntöä on mahdollista tunnistaa suomalaisista yhteisöistä tulleeksi louhintaa kehittämällä (ei vielä toteutettu).
Voidaan siis todeta, että organisaatioiden tunnistamisessa saavutettiin kohtuulliset tulokset ja kattavuus voi olla riittävä palvelun omistajan tarpeisiin. Koska tunnistetuista organisaatioista päästään eteenpäin muihin kiinnostaviin dimensioihin (mm. yhteisöiden toimialaluokitteluun), tällainen automatisoitu asiakaskategorisointi on realistinen verrattuna manuaaliseen kategorisointiin. Toisaalta tulokset osoittavat, että melko yksinkertaisilla mutta fiksuhkoilla (en ehkä rohkenisi sanoa ”älykkäillä”) automatisoinneilla vähennetään manuaalista työtä merkittävästi datan keruussa.
Mitä seuraavaksi?
Meillä on lokianalyysissä siis sellainen tilanne, että ei ole käytettävissä käyttäjätunnistetta (seurantakeksin, käyttäjätunnuksen tms. muodossa), jolla voitaisiin luotettavasti tunnistaa palaavia käyttäjiä. Kun datapyynnöt tulevat yhdestä organisaation verkko-osoitteesta tai operaattorin nimissä olevasta vaihtuvasta osoitteesta, miten voidaan käyttäjiä erotella ja siten pitkällä aikavälilläkin palaavia käyttäjiä havaita? Yksi keino on yrittää muodostaa käyttäjä- ja käyttäjäryhmäprofiileja sen mukaan miten ja millaisia pyyntöjä avoimen datan palveluun tulee. Seuraavassa blogikirjoituksessa katsomme hieman tarkemmin miltä erilaisten käyttäjien lokitiedot näyttävät ja miten voitaisiin havaita samankaltaisten käyttäjien ryhmiä yksittäisten organisaatiotunnisteiden takaa.

Tämän blogin kirjoitti Spatineon Lead Data Scientist Tuomas Lepola. Hänen erikoisalueisiinsa kuuluu osaamista aina koneoppimisesta pilvipalveluihin ja data-analytiikasta tietovirtojen hallintaan.